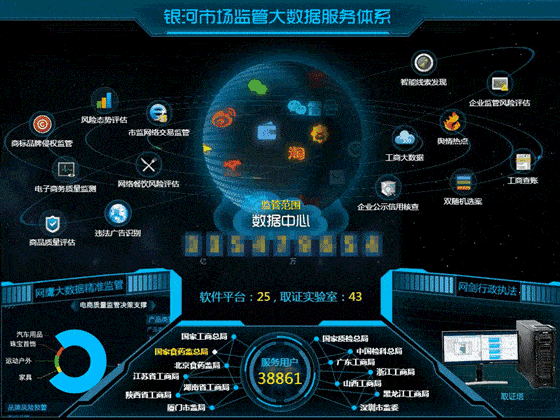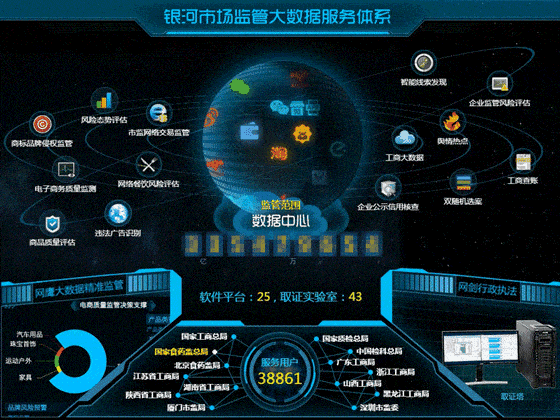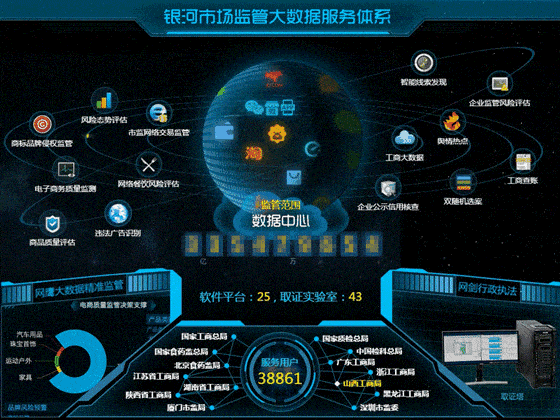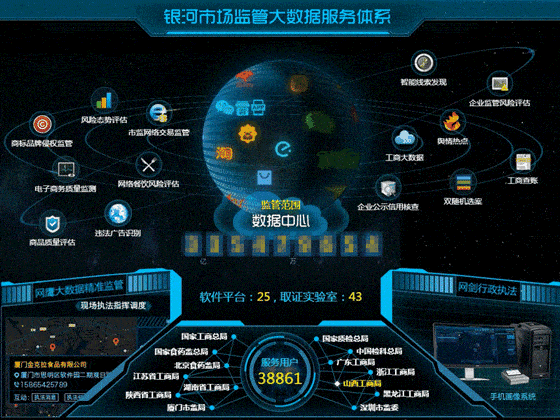
软件开发公司排名极其吃香,也是竞争非常激烈的商业模式。虽然国内软件开发公司有所发展壮大,但是各地软件开发公司的实力和资质还是参差不齐。下面是国内软件开发公司近期排名汇总。1.华胜恒辉科技股份有限公司上市理由:华胜恒辉是一家专注于高端定制软件开发服务和高端建设的服务机构,致力于为企业提供全面、系统的开发和生产解决方案。
在军工领域,合作客户包括:军委联合参谋部(原总参)、军委后勤保障部(原总参)、军委装备发展部(原总装)、装备研究院、战略支援、军事科学院、研究所、航天科工集团、中国航天科技集团、中国船舶重工集团公司、中国船舶重工集团公司、第一研究院、训练装备院、装备技术研究院等单位。
6、网络爬虫的数据 采集方法有哪些?网络爬虫的数据有很多方法采集,包括但不限于以下几种:1 .静态网页采集:通过发送HTTP请求获取网页的HTML源代码,然后使用解析库(如BeautifulSoup)解析HTML,提取所需数据。2.动态网页采集:对于使用JavaScript动态加载数据的网页,可以使用无头浏览器(如Selenium)模拟浏览器的行为,获得完整的渲染网页内容。
4.RSS订阅采集:Some网站提供RSS订阅功能,订阅RSS feeds即可获得更新内容。5.database采集:Some网站将数据存储在数据库中,连接数据库并执行SQL查询语句就可以获取数据。Octopus 采集 device是一款功能全面、操作简单、适用范围广的a互联网data采集device。无论是静态网页采集,动态网页采集还是API接口采集,Octopus 采集都能帮你快速获取所需数据。
7、以下哪些属于集中化大数据平台外部 采集数据1,database 采集传统企业会使用MySQL、Oracle等传统关系型数据库来存储数据。随着大数据时代的到来,Redis、MongoDB、HBase等NoSQL数据库也常用于data 采集。企业通过在采集端部署大量数据库,并在这些数据库之间进行负载均衡和分片,完成大数据-0;2.系统日志采集系统日志采集主要收集公司业务平台产生的大量日常日志数据,供线下和线上大数据分析系统使用。
系统log 采集 tools全部采用分布式架构,可以满足日志数据采集和每秒数百MB的传输需求;3.网络数据采集网络数据采集是指借助网络爬虫或网站 open API从网站获取数据信息的过程。网络爬虫会从一个或几个初始网页的URL开始,获取每个网页的内容,在爬取网页的过程中,不断从当前页面中提取新的URL并放入队列中,直到满足设定的停止条件。
8、什么是大数据 采集平台自然语言处理(NLP)关注的是人类自然语言和计算机设备之间的关系。自然语言处理是计算机语言学的一个重要方面,也属于计算机科学和人工智能领域。文本挖掘与NLP的相似之处在于,它专注于识别文本数据中有趣和重要的模式。但是,两者还是有区别的。首先,这两个概念并没有明确的定义(就像“数据挖掘”和“数据科学”一样),它们在不同程度上相互交叉,这取决于你在和谁说话。
如果原文是数据,那么文本挖掘就是信息,NLP就是知识,也就是语法和语义的关系。虽然NLP和文本挖掘不是一回事,但两者仍然有着密切的联系:它们处理的是相同的原始数据类型,在使用上有很多重叠。我们的目的不是两者的绝对或相对定义,但重要的是要认识到这两个任务下的数据预处理是相同的。试图消除歧义是文本预处理的一个重要方面。我们希望保留原意,同时消除噪音。
9、如何通过网络爬虫获取 网站数据?Octopus采集device是一款功能全面、操作简单、适用范围广的互联网Data采集device,可以帮助您快速获取网站 data。以下是章鱼哥网站 data 采集的步骤:1。打开Octopus 采集并新建一个采集。2.在任务设置中,输入采集的网址作为采集的起始网址。3.配置采集 rule。可以使用智能识别功能让Octopus自动识别页面的数据结构,也可以手动设置采集 rule。
5.设置翻页规则。如果需要采集多页数据,可以设置Octopus 采集 device自动翻页获取更多数据。6.运行采集 task。确认设置正确后,可以启动采集任务,让章鱼启动采集 data。7.等待采集完成。八达通会根据设定的规则自动抓取页面上的数据,并保存到本地或导出到指定的数据库。Octopus 采集还提供了丰富的教程和帮助文档,帮助用户快速掌握采集的技能。
10、数据 采集data 采集,要注意以下几个方面:(1)准时(及时)。监测数据应按照一定的监测频率或预报需要及时-0。(2)综合性。每次都应收集与监测滑坡和影响因素有关的所有数据。(3)准确。确保每个记录都是准确的。如果现场发现明显错误,应进行复测;尽可能消除人为和机械错误。Octopus 采集 device是一款功能全面、操作简单、适用范围广的a互联网data采集device。
2.在任务设置中,输入采集的网址作为采集的起始网址。3.配置采集 rule,可以使用Octopus的智能识别功能自动识别页面的数据结构,也可以手动设置采集 rule。4.如果选择手动设置采集规则,可以用鼠标选中页面上的数据元素,设置对应的采集规则,以确保能够正确获取所需的数据,5.设置翻页规则。如果需要采集多页数据,可以设置Octopus 采集 device自动翻页获取更多数据。
文章TAG:采集 互联网 网站 大型 综合 互联网大型综合网站数据资源采集














